일반적으로 알려진 Hive 성능을 높이기 위한 방안 알려진 방안 HDP를 사용할 경우
[Tez Engine 사용] (현재 사용중)
MR(Map Reduce)는 여전히 대용량 배치 작업에 사용되고 있지만 이제 구 시대의 기술이 되어 버렸죠. Tez 엔진을 사용하면 2배 이상의 성능 향상이 가능 함
[ORC File 사용] (현재 사용중)
일반적인 TEXT FILE 형태로 HIVE Table에 데이터를 넣는 것 보다 ORC File 형태로 입력하면 좀더 나은 성능을 얻을 수 있다. 일반적으로 Hive Table을 생성 할때
“CREATE TABLE TESTTABLE (value string, key string) STORED AS ORC” 만들고
“insert OR Load Data”를 사용하여 TABLE에 입력하면 된다.
추가적으로 SNAPPY 압축을 걸어 줄 수 있다.
“CREATE TABLE TESTTABLE (value string, key string) STORED AS ORC TBLPROPERTIES (“orc.compress”=”SNAPPY”)”
ORC 파일 형태의 파일이 TEXT 파일 형태보다 용량을 1/4정도 절감 할 수 있습니다. 여기에 SNAPPY 압축으로 데이터 용량을 더 줄이는 것이 가능 하다
[VECTORIZATION 사용] (현재 사용중)
Hive Configuration에 존재 하는 항목 이다.
hive.vectorized.execution.enabled = true
hive.vectorized.execution.reduce.enabled = true
위와 같이 설정하면 VECTORIZATION을 사용 가능 하다
VECTORIZATION은 ‘like’ scan, aggregations, fliters and joins의 성능 향상을 가져 온다
[PARTITION 사용] (현재 미사용)
PARTITION은 특정 키를 기준으로 HDFS에 저장되는 파일의 위치를 분리 한다.
QUERY 수행 시 PARTITION KEY를 Filter 조건으로 걸어 주면 해당 지역의 파일만 스캔하여 분석을 하기 때문에 빠른 응답 속도를 보인다.
하지만 FULL SCAN QUERY의 경우 속도 저하가 발생합니다.
그리고 PARTITON으로 분할 입력 시 HDFS내에 파일 내에 개수가 증가하게 될 경우 작은 용량의 파일의 개수가 증가하면서 FILE I/O 부하가 증가하여 전체적인 속도 저하가 크게 발생하게 된다.
지금까지 PARTITON을 사용 하는 것 보다 FULL SCAN QUERY를 사용 하는 것이 더 빠른 양의 데이터(ㅡㅡ)였기에 사용하지 않고 있었지만 데이터의 증가가 빠르게 이루어 지고 있는 만큼 적용 후 테스트를 더 진행해 봐야 할 것 같다.
[COST BASED QUERY OPTIMIZATION 사용]
QUERY 수행 PLAN을 최적화 하여 사여 EXCUETION 하도록 하는 기능 이다.
Configuration
hive.cbo.enable=true
hive.compute.query.using.stats=true
hive.stats.fetch.column.stat=true
hive.stats.fetch.partition.stat=true
위 설정으로 사용 가능 하며 현재 설정되어 있는 옵션
분석을 원하는 Table 에
analyze table [tablename] compute statistics
analyze table [tablename] compute for columns;
명령어를 하면 각 컬럼에 대한 통계 데이터를 생성하여 최적의 쿼리 PLAN을 찾아 준다고 한다.
[쿼리 최적화]
가장 중요한 것은 쿼리 최적화 이다. 쿼리를 작성 할 때 나도 가끔 잊곤 하는 것이 있는데..
항상 explain 으로 쿼리 plan을 확인 하는 습관이 필요 하다.
아무리 최적화를 한다고 해도 쿼리를 잘 못 짜면 아무 소용이 없다.
UDF Function 도 마찬가지…
[간단한 테스트]
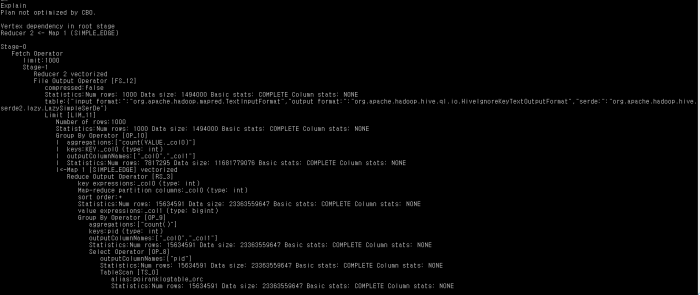
TABLE을 분석 하기 전
select pid , count(*) from poiranklogtable_orc group by pid limit 1000
QUERY의 execute plan 이다.
눈여겨 볼 것은 맨 위 상단의
Plan not optimized by CBO
Reducer 2 Vectorized
Map 1 vectorized
이다. 위에서 언급 했던 vectorization이 적용 되어 있다고 하고 CBO로 최적 화 되지 않았다고 나온다.
쿼리 수행 시간 : 60.429
“analyze table poiranklogtable_orc compute statistics for columns” 실행 후
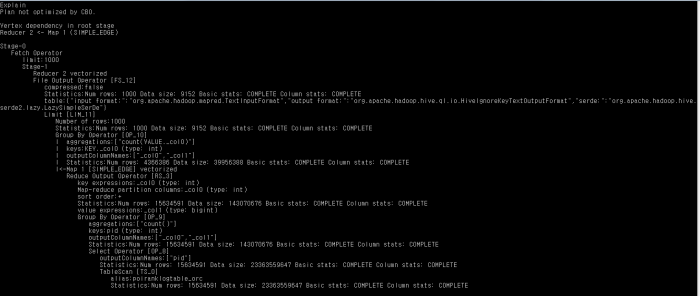
겉으로 보기에는 별 차이가 없어 보인다.
상단에 Plan not optimized by CBO 도 그대로 보인다.
Statistics:Num rows: 4366386 Data size: 39956388 Basic stats: COMPLETE Column stats: COMPLETE
자세히 살펴보면 위와 같이 group by operator 에서 Data Size와 Num Rows의 개수가 줄었다.
쿼리 수행 시간 : 47.33
CBO 를 사용하기 위해서 analyze 명령을 수행해야 하는데 이 수행 명령 또한 소요 시간이 발생한다. (위의 Table에서는 소요 시간 32초 즉 전체 수행 시간: 32+47 = 79)
그냥 analyze를 사용한다고 해서 optimized 하게 모든 plan이 다 적용 되는 것도 아닌 것 같다. 데이터가 적재 될 때 마다 분석 쿼리를 수행해야하는 지도 불분명 하다.
CBO기능은 좀더 확인을 해봐야 할 듯 하다.
'프로그래밍 > hive' 카테고리의 다른 글
| Hive MIN/MAX STRUCT 쿼리 사용 (0) | 2017.12.25 |
|---|---|
| Hive CLI 기본 셋팅 (0) | 2017.12.25 |
| Hive Command Line CLI History 보기 (0) | 2016.06.07 |
| Hive GenericUDTF 사용 (0) | 2016.05.13 |
| HDP Hiveserver2 JAVA heap Error (1) | 2016.03.30 |